

Los postes de la portería se han movido en los mercados de capitales con el lanzamiento de ChatGPT. No soy el primero en decir esto, y algunos dirían que soy un mono exagerado. Sin embargo, lo creo y eventos como este no suceden todos los días. Manteniéndose al margen del campo deportivo, los ejecutivos de los mercados de capital reevaluarán sus jugadas a balón parado e identificarán nuevas tácticas para determinar ganadores y perdedores en medio de un tornado de cambios. He experimentado tres cambios de este tipo en mi carrera profesional, la creación de nuevos instrumentos financieros, luego la introducción de HFT y la ola de regulación posterior a GFC. Lo interesante es que en los tres casos, la IA estaba al margen, con el sustituto desesperado por cambiar el juego. Cuando lo hizo, los capitanes y los jugadores experimentados en el campo lo mantuvieron bajo control, sin importar cuán emocionante fuera el talento.
La IA generativa es un cuarto tornado masivo en la carrera, y con él, la IA impulsa el juego. Siguiendo la analogía de los deportes, reúne a un supersumiso alto, el talento verificado hasta ahora de la IA discriminatoria, que impulsa el juego con el chico nuevo en el bloque con aparentemente potencial ilimitado – IA generativa. Juntos brindan creatividad, contenido y, solo cuando juegan juntos, respuestas procesables que generan valor. Ya no son los envejecidos Lionel Messis y Tom Bradys (no nombraré a ninguno) de Capital Markets los que impulsan las nuevas monedas. Supersubs y wizzkids de todos los géneros y etnias están en la ciudad, revitalizando una industria relativamente estática.
Exploremos cómo la IA discriminativa y generativa se comparan, difieren y refuerzan entre sí.
En pocas palabras, ambos se basan en modelos de aprendizaje automático y profundo que buscan comprender y aprender de los datos, e implementar esa comprensión en otras situaciones. En el caso de la nueva IA generativa joven y emocionante, se crean nuevos datos en forma de texto, código, música y otros tipos de contenido, mientras que la IA discriminatoria, mundana y evolucionada durante muchos años encuentra respuestas y soluciones reales en nuevos conjuntos de datos
Cuando los dos tipos de IA se cruzan, ahí es donde ocurre la magia. Del lado de GenAI, los modelos de lenguaje grande (LLM), del lado de la IA discriminatoria, los modelos de datos grandes (los llamaré LDM en el resto de este artículo por simplicidad, pero no deben confundirse con los modelos de datos lógicos, que es un uso común de las siglas LDM y significa algo diferente). Cuando los LLM y LDM se implementan juntos, articulan tanto soluciones específicas valiosas como escenarios, contexto y significado ricos en contenido.
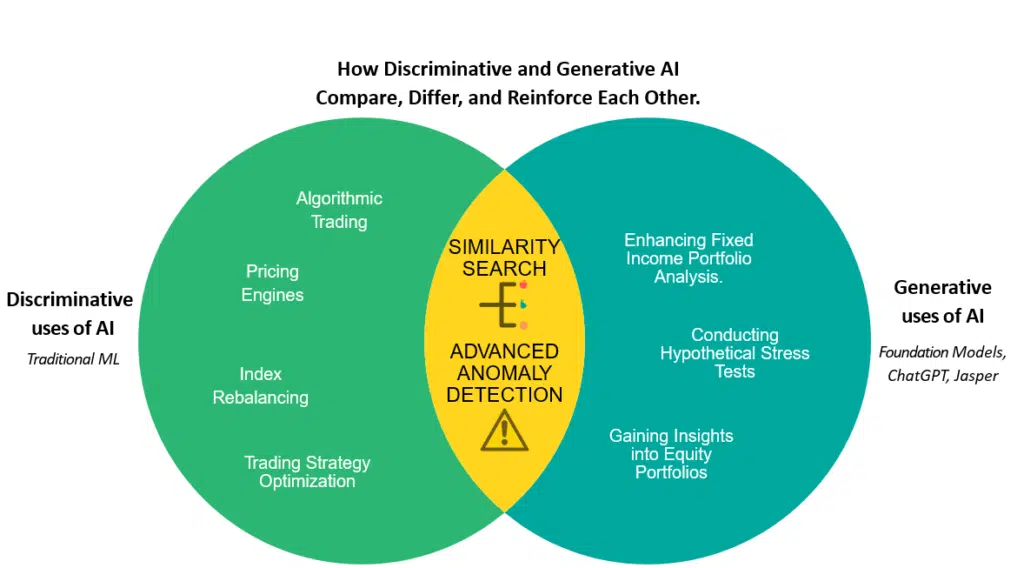
A continuación, exploramos tres casos de uso clave del mundo real identificados en los mercados de capitales. Mostramos cómo combinan los dos tipos de IA para ayudar a los profesionales financieros a tomar decisiones informadas, teniendo en cuenta el contexto. Estos no son casos imaginarios del arte de lo posible, sino escenarios reales en los que los corredores y los ejecutivos de compras están trabajando mientras escribo.
Ejemplo 1: Mejora del análisis de la cartera de renta fija.
Considere un escenario en el que un banco valora una cartera de bonos que consta de 100 bonos OTC, cada uno con términos no estándar integrados en documentos PDF. Pueden solicitar a los LLM, a través de codificadores conocidos como integraciones vectoriales, que clasifiquen y categoricen estos enlaces con bastante precisión. Al trabajar directamente con datos (MLD) y combinar la búsqueda de similitudes con técnicas prescriptivas como la optimización, el banco puede identificar información de precios para instrumentos que se asemejan mucho a los componentes de la cartera. Un aviso relevante de un administrador de cartera podría ser: “¿Me puede dar detalles de precios y un resumen de los riesgos (liquidez, contraparte/riesgo de crédito, riesgo de mercado) para la cartera, así como la confianza?”
Ejemplo 2: Obtener información sobre carteras de acciones
Para los inversores que gestionan carteras de acciones, supongamos que tiene una cartera de 30 acciones y desea analizar la exposición. Implemente un aviso como “Según mi cartera, ¿cuántos ingresos genera la región de la ASEAN hoy?” o “¿Podría proporcionarme un gráfico circular de los empleados desglosados por país de mi cartera?” Además, puede sumergirse en los factores ESG para estimar cómo se clasifican las empresas de su cartera desde una perspectiva de género, por ejemplo. En este caso, una base de datos vectorial central, suponiendo que pueda manejar múltiples tipos de datos vectoriales, representaciones vectoriales codificadas configuradas e indexadas, y datos vectoriales que incorporen directamente la serie temporal de los componentes de la cartera y todos los factores que la acompañan, podría dirigir un aviso en consecuencia a través de el LLM o LDM. Por ejemplo, el LLM puede sugerir nuevos factores ESG, pero el LDM puede funcionar directamente en el universo de factores de su organización.
Ejemplo 3: realizar pruebas de estrés hipotéticas
Al aprovechar los eventos históricos del mercado y los datos en tiempo real, los LLM y LDM pueden ayudar a comprender los posibles resultados de la cartera, por ejemplo, mediante la realización de pruebas de estrés hipotéticas. Suponga que tiene una cartera de 30 acciones y desea evaluar el impacto de eventos específicos. Solicite “¿qué pasaría con mi billetera si AWS pierde ingresos la próxima semana?” o “¿Cómo se vería afectada mi cartera si el BCE subiera inesperadamente las tasas de interés la próxima semana?” Además, puede identificar acciones específicas en el universo de su cartera con la mayor sensibilidad de precios a eventos como una violación de datos con solo presionar un botón o un aviso verbal. Es empoderador. Una vez más, dicho análisis contextual se basa en la inferencia LLM para crear escenarios de forma creativa, pero puede infundirlo con los datos de su mercado y cartera.
La importancia de una base de datos vectorial que maneja más que solo, ejem, vector (incrustaciones)
En los casos de uso anteriores, introduje la noción de una base de datos vectorial sin explicarla realmente. La palabra vector es un término sobrecargado en matemáticas e informática. Por un lado (principalmente matemático) es una forma sencilla de entender magnitud y dirección, por ejemplo en geometría y mecánica. Por otro lado (principalmente en informática), un vector representa una secuencia de números, tal vez números diarios altos, bajos o cercanos, por ejemplo, y puede tener una longitud infinitesimal. Para aquellos que usan lenguajes de programación matemática como R, MATLAB, NumPy (Python), Julia, o q, este último les resulta familiar aunque probablemente también hayan estudiado matemáticas, por lo que también entienden los primeros.
El nuevo tipo de base de datos vectorial que impulsa el modelo de lenguaje grande (y puede impulsar un modelo de datos grandes) es una especie de mezcla de los dos. Toma la noción de un “vector incrustado” que codifica su cosa (a través de un proceso de entrenamiento de red neuronal), ya sea una palabra o un concepto, en una secuencia de números asignados o derivados, más que solo magnitud y dirección. Su base de datos de vectores puede buscarla y recrear las palabras, el código, la cosa, junto con otras cosas similares para implementar contenido integrado. Sin embargo, la noción de incrustación de vectores no es nueva. Estaba demostrando las capacidades de la biblioteca word2vec (significa Word to Vector) alrededor de 2015 para crear estrategias comerciales basadas en la semántica, aprovechando los eventos de tweet, por ejemplo. Qué rápido olvidamos estas cosas.
Sin embargo, para usuarios de R, MATLAB, NumPy Julia y q, es limitado. Los vectores manejan series de tiempo, datos secuenciados y realmente ayudan a modelar la distancia y la magnitud. También permiten operaciones matemáticas rápidas, llamadas procesamiento de vectores, que lo ayudan a manipular los datos mucho más rápido y de manera más eficiente que con los bucles formales (como en C++) o las consultas basadas en filas (como con SQL) que dominan tanto. de la informática moderna. Así es también como los cuantitativos tienden a entender los datos de su cartera, datos comerciales, datos de mercado, datos de riesgo, datos de eventos y mucho más. De esta manera, el procesamiento vectorial tiende a caer dentro del ámbito del álgebra lineal y el álgebra matricial, la base conceptual no solo de las finanzas cuánticas, sino también de los ingenieros que diseñan sistemas de control, procesamiento de datos, imágenes y videos (las imágenes son matrices de datos, con secuencias de videos a lo largo del tiempo), procesamiento de señales (cómo las señales, por ejemplo, los sonidos, cambian con el tiempo) y los sistemas dinámicos en general. El álgebra matricial también define los protocolos de secuenciación detrás de las redes neuronales, lo mismo (matemático) que impulsa LLM.
Entonces, en mi opinión, una base de datos vectorial adecuada maneja tanto las integraciones vectoriales como el procesamiento vectorial, y de esta manera debería poder procesar LLM además de los datos reales más allá de las integraciones vectoriales LLM, el modelo de big data.
La mayoría de las nuevas bases de datos vectoriales se centran en la primera, que creo que es inútil más allá de ser una especie de memoria histórica para un LLM. Las bases de datos vectoriales adecuadas, si son fieles a sus raíces vectoriales, hacen ambas cosas y, por lo tanto, admiten lenguajes grandes y modelos de datos grandes.
El futuro es brillante para los vectores, que por cierto se remonta a Turing y sus ambiciones para el motor de computación automática (ACE), además de los fundamentos clave de la computación matemática y la ingeniería de control, por lo que, en muchos sentidos, volvemos a nuestros viajes.